India's value-for-money IT hardware brand
14 years. 28,000 sq ft. 100,000+ devices. From desktops to data center — designed, engineered, and manufactured in India.
Why choose RDPDesktops to data center, all Make in India
14 product categories across compute, AI, and data center. Deployment-ready from our 28,000 sq ft facility.
Download Product CatalogSovereign AI infrastructure
End-to-end AI compute under one sovereign umbrella. Designed here. Manufactured here. Supported here.
Talk to a Solutions Architect
SLA-driven. Not ticket-driven.
Warranty. SLA. On-site service. Account management. Every commitment documented, every response time defined.
Download SLA Commitment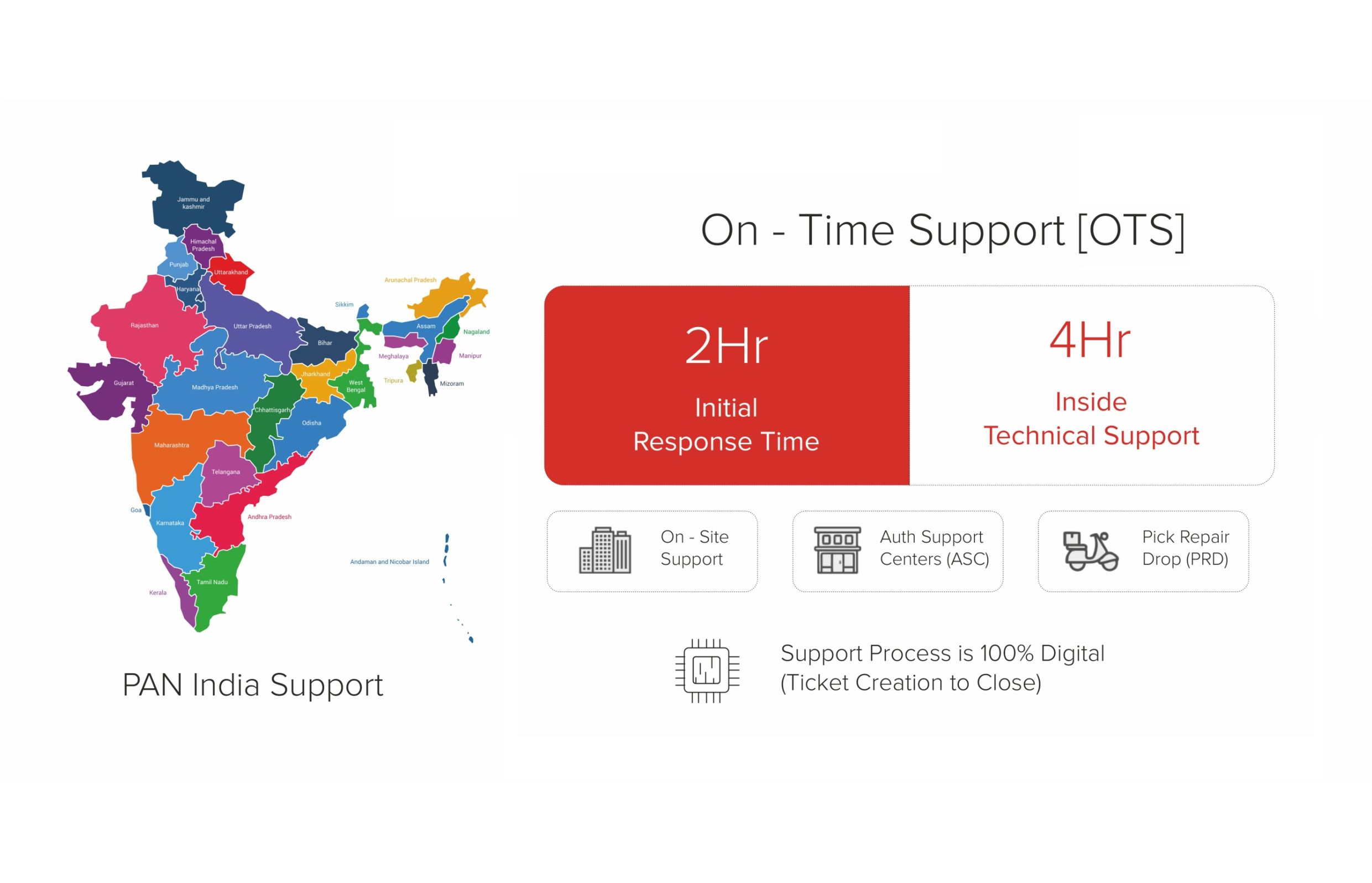
Built on process, not promises
ISO 9001. PLI 2.0. SOP-led manufacturing. The systems behind every device we ship.
Our Story
GPU-accelerated platforms.
Built for AI at scale.
5 pre-validated NVIDIA-powered GPU servers spanning workstation-class 1U to flagship 8U HGX B300. Engineered for LLM training, AI inference, HPC, and computer vision — with NVIDIA Blackwell and Hopper architectures.
Large language models. Generative AI. Computer vision. HPC. Real-time inference. Shipping in 5 business days.
Four GPU server families.
From workstation-class single-GPU systems to NVIDIA HGX B300 flagships — choose the platform that matches your AI workload profile.
HGX
NVIDIA HGX B300 reference design — 8 SXM-form GPUs interconnected via fifth-gen NVLink for maximum bandwidth. The flagship platform for foundation model training.
- Up to 8× NVIDIA HGX B300 GPUs
- Fifth-gen NVLink fabric (1.8 TB/s GPU-GPU)
- 3TB DDR5 + 1.4TB HBM3e GPU memory
- 8× XDR800 InfiniBand for cluster scale-out
- Air-cooled and liquid-cooled options
MGX
NVIDIA MGX modular reference architecture — standardized 2U platform for B200 GPUs that scales linearly. Optimized for AI inference and cluster deployments.
- NVIDIA MGX B200 GPU platform
- Standardized modular building blocks
- Up to 24× E1.S NVMe storage
- 200/400GbE or NDR InfiniBand networking
- Rack-scale deployment in days
PCIe-Based GPU
Traditional 4U dual-CPU platforms with up to 8× PCIe Gen5 GPUs. Maximum flexibility — mix RTX PRO 6000, H200 NVL, L40S, or custom GPU configurations.
- Up to 8× double-width PCIe 5.0 GPUs
- NVIDIA RTX PRO 6000 Blackwell & H200 NVL
- Dual Intel Xeon 6 or AMD EPYC 9005 CPUs
- Up to 3TB DDR5-6400 system memory
- Tool-less, hot-swap drive bays
Workstation-Class AI
Compact 1U rackmount with workstation-grade GPU and CPU — perfect for edge AI inference, AI development workstations, and departmental ML/data science teams.
- NVIDIA RTX PRO 4000 / L4 GPU options
- AMD Ryzen Threadripper / Intel Xeon W
- Up to 256GB DDR5 ECC memory
- 1U short-depth · Office-friendly acoustics
- Pre-installed CUDA, cuDNN, ML frameworks
5 pre-validated AI configurations.
Filter by GPU count or form factor to shortlist the right R Series AI platform — every system ships pre-configured and validated.

HGX B300 8-GPU AI Training Flagship
The flagship platform for foundation model training and the most demanding generative AI workloads. 8× SXM-form HGX B300 GPUs with fifth-gen NVLink.

4× Blackwell RTX PRO 6000 Inference
Best-in-class AI inference platform with 4× NVIDIA RTX PRO 6000 Blackwell GPUs. Optimized for LLM serving, computer vision, and creative AI workloads at scale.

8× H200 NVL PCIe Training & Inference
Dense 4U platform with 8× NVIDIA H200 NVL GPUs (141GB HBM3e each). Balanced training and inference platform with up to 1.1TB of GPU memory.

MGX B200 Modular AI Compute
NVIDIA MGX modular reference architecture in a dense 2U form factor. Standardized building block for rack-scale AI clusters with linear scaling and rapid deployment.

Workstation-Class AI for Edge & Dev
Compact 1U platform with workstation-grade NVIDIA RTX PRO 4000 GPU. Perfect for AI development, departmental ML/data science teams, and edge AI inference.
Pre-validated for AI workloads.
Every R Series AI SKU is engineered and tested for specific AI workload patterns — from foundation model training to real-time inference.
Foundation Model Training
Large-scale training of LLMs, vision-language models, and foundation models on multi-GPU clusters with NVLink fabric.
- Multi-billion parameter LLM training
- Vision-language models (CLIP, BLIP)
- Diffusion model training
- Distributed training across 100s of GPUs
LLM Inference at Scale
High-throughput, low-latency serving of large language models for production AI applications and enterprise copilots.
- GPT-class model serving (70B+ params)
- Enterprise copilots & chatbots
- vLLM, TGI, TensorRT-LLM optimized
- Real-time RAG pipelines
Computer Vision & Video AI
Real-time computer vision, video analytics, and multimodal AI pipelines for security, retail, and industrial use cases.
- Real-time object detection & tracking
- Video analytics for security & retail
- Medical imaging & pathology AI
- Industrial quality inspection
Generative AI & Creative
Image, video, 3D, and audio generation workloads for creative industries, marketing, and content production.
- Stable Diffusion & Flux image generation
- Text-to-video generation
- 3D asset generation (NeRF, Gaussian Splat)
- Audio synthesis & voice cloning
Scientific Computing & HPC
GPU-accelerated scientific simulation, computational physics, drug discovery, and climate research workloads.
- Molecular dynamics & drug discovery
- Climate & weather modeling
- Computational fluid dynamics
- Genomics & bioinformatics
AI Development & Edge AI
Compact workstation-class platforms for AI development teams, ML data science workstations, and edge AI inference.
- Departmental ML/data science workstations
- Edge AI inference (retail, factory floor)
- AI prototyping & development
- Computer vision at the edge
Why R Series for AI infrastructure
Four reasons enterprises standardize on R Series for production AI infrastructure.
Pre-Validated & CUDA-Ready
Every system ships with NVIDIA drivers, CUDA toolkit, cuDNN, and popular ML frameworks (PyTorch, TensorFlow, JAX) pre-installed and validated. Power-on to first training run in minutes.
Latest NVIDIA Architectures
NVIDIA Blackwell (B300, B200, RTX PRO 6000), Hopper (H200 NVL), and Ada Lovelace (L40S, RTX PRO 4000) — current-gen across the portfolio with full NVLink fabric support.
5-Day Ship · Production-Ready
Pre-built from our Hyderabad facility, ready to ship in 5 business days. Unpack, rack, connect networking — your AI cluster is live and training within hours.
3/3/1 Warranty · Make in India
Three years parts, three years labor, one year cross-ship standard. Designed and supported from India with PAN-India SLA service network for sovereign AI deployments.
Spec your AI cluster in days, not months.
Tell us your AI workload — foundation model training, inference at scale, or edge AI. Our AI architects will spec the right R Series configuration.